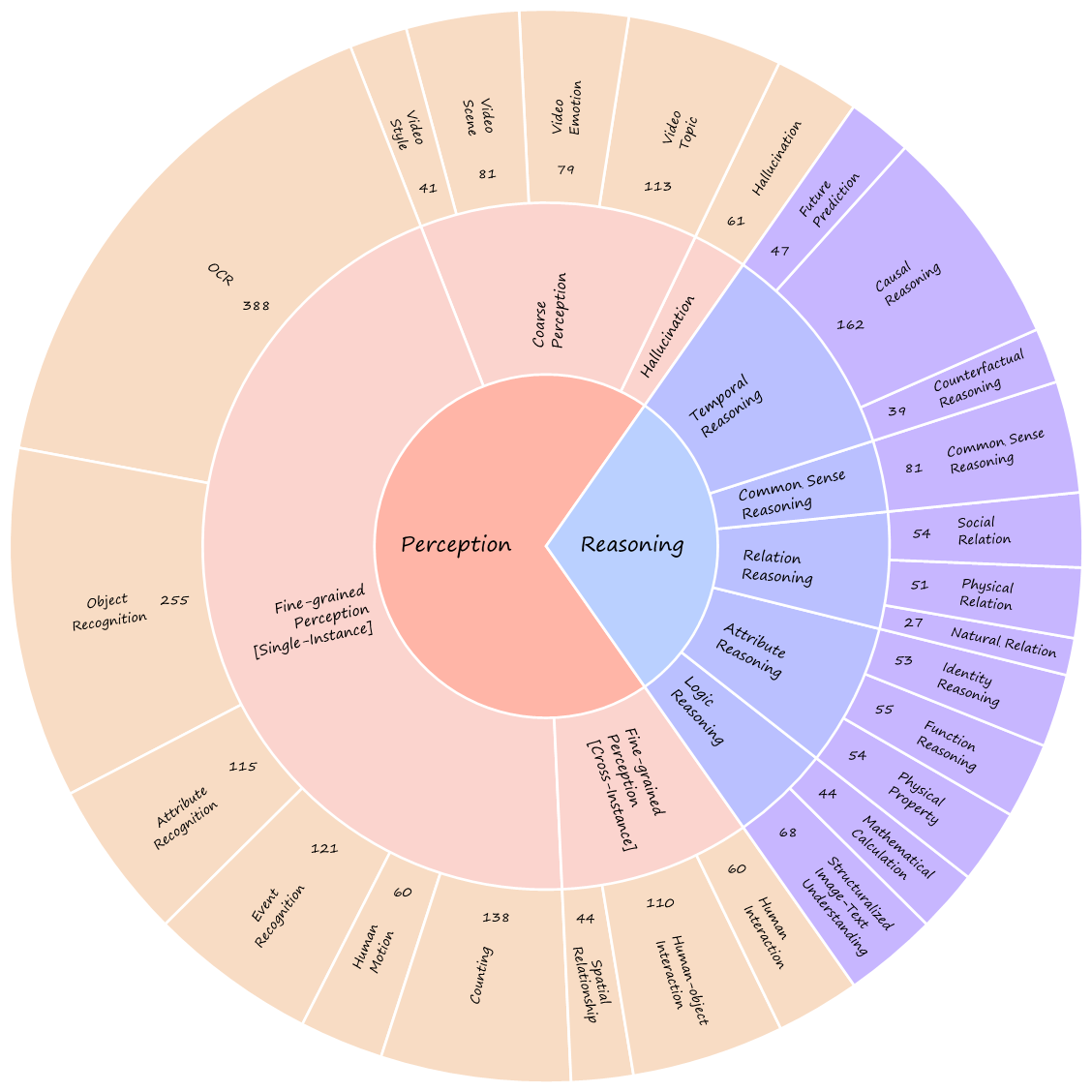
Perception: CP (coarse perception), FP-S (single-instance fine-grained perception), FP-C (cross-instance fine-grained perception), HL (Hallucination)
Reasoning: LR (logic reasoning), AR (attribute reasoning), RR (relation reasoning), CSR (commonsense reasoning), TR (temporal reasoning)
The best results are highlighted in bold and underlined.
You can also view the latest MMBench-Video Leaderboard at OpenVLM Video Leaderboard!
| Model | Perception | Reasoning | Overall Mean | Model Type | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CP | FP-S | FP-C | HL | Mean | LR | AR | RR | CSR | TR | Mean | |||
| GPT-4o-0806-[16f] 🥇 | 2.04 | 1.89 | 1.66 | 2.15 | 1.89 | 1.75 | 2.04 | 1.81 | 1.93 | 1.62 | 1.81 | 1.87 | Proprietary LVLMs for Images |
| Gemini-1.5-Flash-[16f] 🥈 | 1.77 | 1.69 | 1.52 | 1.29 | 1.66 | 1.46 | 1.88 | 1.78 | 1.75 | 1.39 | 1.63 | 1.66 | Proprietary LVLMs for Images |
| Aria-[16f] 🥉 | 1.84 | 1.63 | 1.40 | 0.95 | 1.61 | 1.22 | 1.88 | 1.71 | 1.59 | 1.48 | 1.58 | 1.61 | Open-Source LVLMs for Images |
| VILA1.5-40B-[14f] 🥉 | 1.78 | 1.72 | 1.35 | 0.47 | 1.63 | 1.12 | 1.78 | 1.61 | 1.48 | 1.45 | 1.52 | 1.61 | Open-Source LVLMs for Images |
| InternVL2-76B-[16f] | 1.76 | 1.66 | 1.38 | 0.35 | 1.59 | 1.40 | 1.81 | 1.73 | 1.70 | 1.41 | 1.59 | 1.59 | Open-Source LVLM for Images |
| Claude-3.5-Sonnet-[8f] | 1.57 | 1.39 | 1.07 | 1.40 | 1.38 | 1.13 | 1.70 | 1.48 | 1.54 | 1.04 | 1.35 | 1.38 | Proprietary LVLMs for Images |
| mPLUG-Owl3-[16f] | 1.56 | 1.42 | 1.18 | 0.35 | 1.37 | 0.89 | 1.55 | 1.42 | 1.31 | 1.18 | 1.28 | 1.35 | Open-Source LVLM for Images |
| VideoChat2-HD-[16f] | 1.45 | 1.19 | 1.12 | 0.44 | 1.20 | 0.84 | 1.49 | 1.39 | 1.11 | 1.23 | 1.23 | 1.22 | Open-Source LVLM for Videos |
| Phi-3.5-Vision-[16f] | 1.44 | 1.26 | 0.93 | 0.48 | 1.22 | 0.81 | 1.42 | 1.28 | 1.12 | 0.90 | 1.11 | 1.20 | Open-Source LVLM for Images |
| PLLaVA-34B-[16f] | 1.41 | 1.18 | 0.93 | 1.00 | 1.19 | 0.66 | 1.43 | 1.25 | 1.28 | 1.10 | 1.16 | 1.19 | Open-Source LVLM for Videos |
| LLaVA-NeXT-Video-34B-HF-[32f] | 1.35 | 1.15 | 0.97 | 0.58 | 1.14 | 0.64 | 1.38 | 1.30 | 1.27 | 1.03 | 1.13 | 1.14 | Open-Source LVLM for Videos |
| VideoStreaming-[64f+] | 1.38 | 1.13 | 0.80 | 0.32 | 1.13 | 0.77 | 1.27 | 1.11 | 1.01 | 1.10 | 1.09 | 1.12 | Open-Source LVLM for Videos |
| LLaMA-VID-7B-[1fps] | 1.30 | 1.09 | 0.93 | 0.42 | 1.09 | 0.71 | 1.21 | 1.08 | 0.83 | 1.04 | 1.02 | 1.08 | Open-Source LVLM for Videos |
| Chat-UniVi-7B-v1.5-[64f] | 1.32 | 1.08 | 0.87 | 0.40 | 1.08 | 0.57 | 1.19 | 1.03 | 0.90 | 1.01 | 0.99 | 1.06 | Open-Source LVLM for Videos |
| ShareGPT4Video-8B-[16f*] | 1.20 | 1.05 | 1.00 | 0.32 | 1.04 | 0.89 | 1.06 | 1.19 | 1.01 | 0.99 | 1.03 | 1.05 | Open-Source LVLM for Videos |
| Video-LLaVA-[8f] | 1.17 | 1.06 | 0.84 | 0.42 | 1.04 | 0.54 | 1.24 | 1.02 | 0.72 | 0.96 | 0.95 | 1.03 | Open-Source LVLM for Videos |